앞서 라이브러리에 대해 언급한 적 있는데요. 많은 라이브러리들이 무료로 공개되어 있습니다. 이중에 어떤 라이브러리를 선택하는 것이 효율적일까요?
라이브러리를 선택할 때 고려할 점?
1. 개발하려는 제품, 원하는 결과를 얻기에 충분한 성능을 지녔는가
2. 인기가 많은 라이브러리인가 - 버그 수정이 빠르고 데이터가 많음
3. 사용해 봤을 때 편리하고 나의 효율을 높여주는가
유명 머신러닝 라이브러리
- scikit-learn : 전통적인 머신러닝 알고리즘 사용 목적으로 사용
- Tensorflow : 주로 딥러닝 목적으로 사용
- Pytorch, Keras, Caffe, Theano, DL4Jd ...

그 중 이번 포스팅에서 알아볼 사이킷런은 파이썬의 머신러닝 라이브러리입니다. (텐서플로는 딥러닝)
사이킷런에서 제공하는 모듈은 지도/비지도학습 모듈, 모델 선택 및 평가를 위한 모듈, 데이터 변환 및 데이터를 불러오기 위한 모듈, 계산 성능 향상을 위한 모듈 등이 있습니다.
사이킷런 역시 다른 라이브러리에 의존성을 가지고 있는데요, 이전에 Numpy와 Scipy를 설치하여 사용하면 됩니다. (아나콘다 설치 시 자동으로 설치 진행됨)
Training Set, Validation Set, Test Set
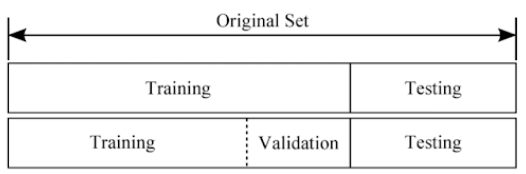

-
Data set (= Original set) :: 러닝 모델의 설계, 학습, 테스트를 위해 확보한 데이터
-
Training Set :: 모델의 학습에 사용되는 데이터
-
Validation Set :: 모델 제작 과정 중, 학습된 모델 성능을 측정하기 위한 데이터
-
Test Set :: 모델의 최종 성능을 평가하기 위한 데이터 / 학습에 영향 주지않음, 모델 제작과 완전히 분리
Trainig Set과 Validation Set 나누기

Train에는 Survived를 제외한 모든 열을 포함, Target에는 Survived만 포함합니다.
train과 valid data를 나누는 비율은 8:2 정도면 적당하다고 알려져 있으나 7:3, 9:1도 무난합니다.

split 할 때 다른 옵션들을 지정할 수 도 있습니다.
Scikit-Learn의 Decision Tree Classifier을 사용하여 학습하기

x_train과 y_train의 열만으로도 학습이 가능하고, 황금계수를 금방 찾아낼 수 있습니다.
Output은 tree의 정확도를 의미합니다.
마지막 score 문장의 경우 "학습된 모델로 x_train의 결과를 얻어낸 다음, 그 예측과 y_train 결과를 비교해 정확도를 보여달라"는 문장입니다.

반복이 진행될 수록 training set accuracy는 증가하고(그러다 어느 수준에서 수렴) valid set accuracy는 감소하는데요.
그 이유는 훈련을 진행할 수록 트리는 train set에 점점 더 적합한 트리가 되기 떼문에, 새로운 데이터는 valid set에 대해서는 맞지 않게 되는 것입니다. 이는 decision tree의 단점이기도 한데 이를 보완하는 방법에 대해서는 다음 포스팅에 언급하도록 하겠습니다.

'Computer Science > Machine Learning' 카테고리의 다른 글
| Getting started with the Scikit-Learn library (0) | 2020.12.14 |
|---|---|
| Dendrograms and Heat Plots (0) | 2020.12.14 |
| Hierarchical Clustering에 대하여 (0) | 2020.12.13 |
| Random Forest 배워보기 (0) | 2020.07.10 |
| 데이터 사이언스 입문 (0) | 2020.06.15 |


